TL;DR
- Claude Opus 4.8 hat Dynamic Workflows in Claude Code gebracht: Claude schreibt on the fly ein JavaScript-Orchestration-Script und spawnt Dutzende bis Hunderte parallele Subagents auf eine Aufgabe, bis zu 1.000 Agents pro Run.
- Ich hab /ultracode plus Dynamic Workflows für ein "Autoresearch auf Steroiden"-Experiment genutzt: rund 200 Subagents, jeder mit eigener These, alle im Wettkampf den besten Eval-Score meines Agents zu schlagen.
- Größter Stolperstein: es kann still die billigeren Haiku-Subagents statt Opus spawnen. Pin dein Modell.
- Größter Hebel: Genauigkeit. Vage Prompts spawnen generische Agents. Die Skill ist Decomposition, nicht Agent-Anzahl.
- Zu den Token-Kosten: ja, das ist heavy. Auf dem Claude Code Max 20x Plan ist es das wert, auf Pro ist es Overkill. Hör auf bei der Anzeige zusammenzuzucken wenn der Output die Kosten schlägt.
Was sind Claude Code Dynamic Workflows in Opus 4.8?
Falls du gerade erst die Headlines zu Claude Opus 4.8 gesehen hast, hier die Ein-Satz-Version: zusammen mit dem Modell-Upgrade hat Anthropic Dynamic Workflows ausgeliefert. Eine Art für Claude Code zu erkennen dass eine Aufgabe zu groß für einen einzelnen Context ist, automatisch ein Orchestration-Script zu schreiben, und viele Subagents parallel laufen zu lassen, die ihre Ergebnisse verifizieren und zusammenführen statt sich durch eine lineare Kette von Prompts zu quälen.
Ein paar Fakten die du vorm Ausprobieren kennen solltest:
- Claude generiert aus deinem Request in natürlicher Sprache ein JavaScript-Orchestration-Script, und eine separate Runtime führt es im Hintergrund aus.
- Ein einzelner Workflow kann Dutzende bis Hunderte parallele Subagents laufen lassen, gedeckelt bei rund 16 gleichzeitig und 1.000 insgesamt pro Run.
- /ultracode dreht den Reasoning-Effort hoch und ist der Schalter den die meisten nutzen um Claude Code in diesen tiefen, Multi-Agent, Fan-out-und-Verify-Modus zu schieben.
- Opus 4.8 treibt außerdem einen Fast Mode an der Opus-Qualität bei höherer Output-Geschwindigkeit hält.
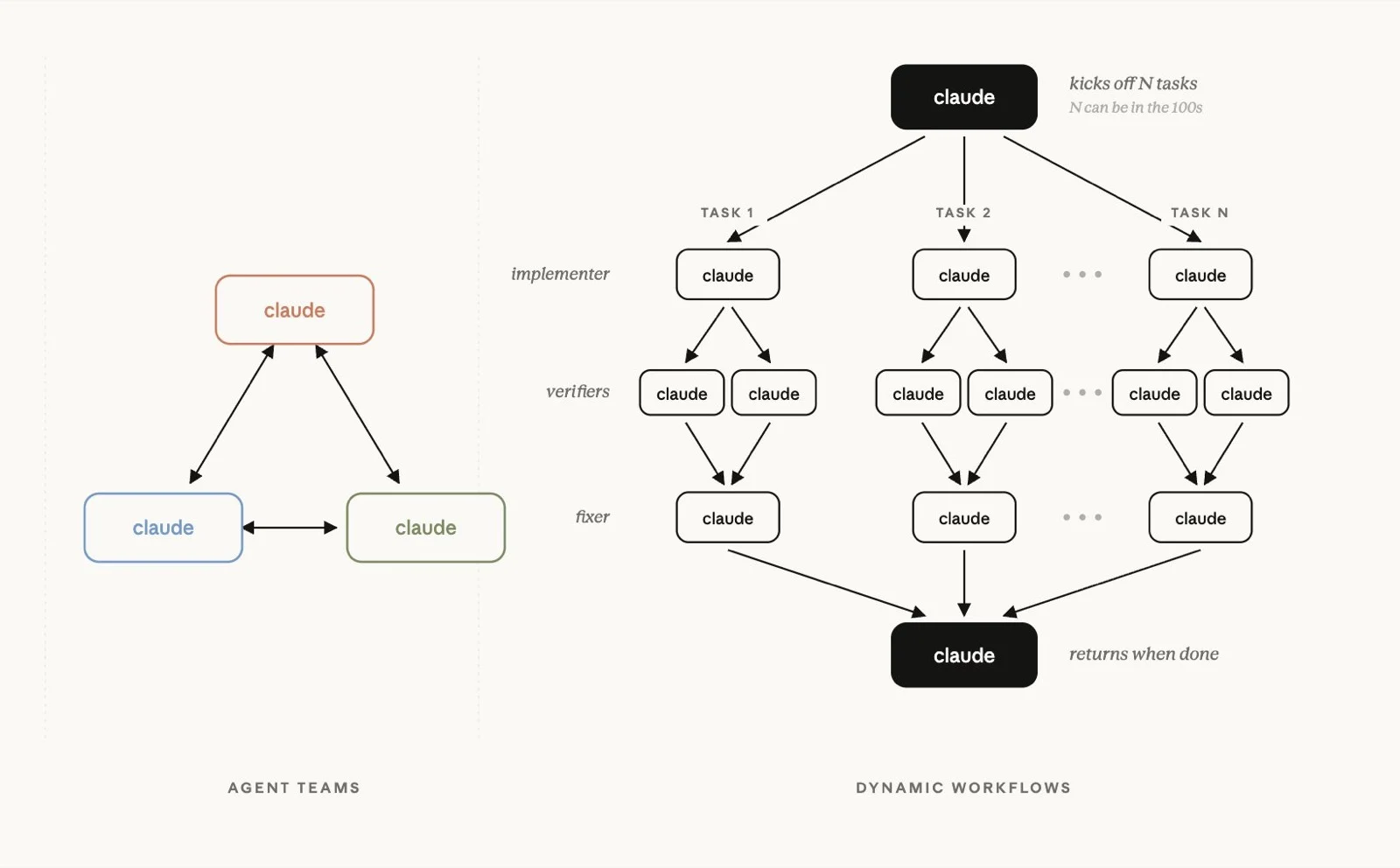
Das ist die Marketing-Schicht. Hier ist wie es wirklich ist damit zu leben.
Die 2-Uhr-nachts-Entscheidung die das angestoßen hat
Ich hatte wochenlang am selben Problem gesessen: die Eval-Scores von einem Agent den ich baue hochkriegen. Nicht glamourös. Einfach der langsame Loop den jeder Practitioner kennt. Ein Knopf drehen, die Suite neu laufen lassen, zuschauen wie eine Zahl sich um 0,3% bewegt, seufzen, den nächsten Knopf drehen. Eine Hypothese nach der anderen, komplett limitiert davon wie schnell ich mir das Nächste ausdenken konnte. Funktioniert, aber ist langsam, und ein bisschen feige, weil du immer nur die Hypothesen testest für die du die Geduld hast.
Ich hatte Karpathys Sachen zu Autoresearch gelesen, ein Modell seine eigenen Experimente vorschlagen und testen lassen. Wie ich da um 2 Uhr nachts saß, mit frisch aktivierten Dynamic Workflows in Opus 4.8, kam ein dummer, unwiderstehlicher Gedanke: was wenn ich Autoresearch nicht brav laufen lasse, eine Idee nach der anderen, sondern voll aufdrehe? Was wenn ich einfach einen Schwarm drauf werfe?
Also hab ich's gemacht. Ich hab einen Workflow geschrieben der Claude Code eine Armee von Agents spawnen ließ, so um die 200, jeder mit seiner eigenen These. Der Job von jedem Subagent war einzig und kompetitiv: schlag den besten Eval-Score den es bisher gibt. Eine andere Hypothese, Config und Perspektive pro Agent. Ein Turnier der Ideen, alle parallel, alle auf der Jagd nach demselben High-Score.
Dem Agenten-Schwarm beim Laufen zuschauen
Ich war nicht ruhig dabei. Ich hab's gestartet und der Orchestration beim Fan-out zugeschaut, ehrlich ein bisschen baff. Zweihundert kleine Researcher, jeder überzeugt seine Idee sei die eine. Manche jagten Varianten die ich irgendwann selbst probiert hätte. Ein Haufen jagte Sachen für die ich mir nie die Mühe gemacht hätte, und ein paar davon waren die die die Zahl bewegt haben.
Das hat das Ganze für mich neu eingeordnet. Wenn du Ideen seriell durchprobierst, explorierst du nicht, du rationierst. Du testest die drei Sachen an die du am meisten glaubst und lässt es gut sein, weil jede einen Nachmittag kostet. Ein Schwarm rationiert nicht. Er probiert die dumm klingende Idee direkt neben der offensichtlichen, weil das Probieren fast nichts kostet, und die dumm klingende Idee gewinnt öfter als meinem Ego lieb ist.
Aber es war nicht "Knopf drücken, Genie empfangen." Hier ist was ich wirklich gelernt hab, mit den Macken zuerst.
Lektion 1: Check welches Modell deine Subagents wirklich fahren
Das hat mich echte Compute gekostet bevor ich's gemerkt hab. Dynamic Workflows spawnen, wenn du sie lässt, still Haiku-Subagents statt Opus. Du denkst also du hast 200 scharfe Researcher und hast eigentlich 200 schnelle, billige, merklich dümmere die das eigentliche Denken machen. Die Thesen-Generierung wird flach, die Experimente werden zaghaft, und du kapierst nicht warum dein brillanter Schwarm Haferbrei produziert.
Das Fiese: nichts wirft einen Error. Keine Warnung, kein fehlgeschlagener Run, einfach still dümmere Research und eine Rechnung dafür.
Takeaway: pin das Modell explizit, pro Agent. Geh nicht davon aus dass Subagents das Hirn deiner Hauptsession erben. Wenn das Denken zählt, und in einem Research-Schwarm ist das Denken das Produkt, sag Opus laut.
Lektion 2: Vage Prompts spawnen generische Agents
Der größte Hebel den ich gefunden hab war nicht die Agent-Anzahl. Es war wie genau ich jeden Subagent spezifiziert hab. Lazy rein ("erkunde Wege den Score zu verbessern") und ich krieg 200 Varianten derselben faden Idee. Bei Schwarm-Skala mittelt sich vage nicht zu Weisheit, es mittelt sich zu Matsch. Hundert fade Agents sind nur ein fader Agent mit einer schlechteren Rechnung.
Gib jedem Agent eine scharfe Rolle, eine konkrete These und echte Constraints ("du glaubst das Problem ist X, teste es unter Bedingung Y, Z darfst du nicht anfassen") und der Output wird richtig gut. Das deckt sich mit dem was Anthropics eigene Guidance zu parallelen Subagents sagt: "nutze 5 parallele Tasks" schlägt "parallelisiere diese Arbeit", und klarer Scope verhindert Überlappung.
Wöchentliche Insights zu AI-Architektur. Kein Spam.
Das Mental Model das es freigeschaltet hat: mehr Compute ist nicht ein Agent der härter denkt, es ist mehr Agents die parallel laufen. Compute ist ein Regler, keine Rechnung. Sobald das klickt, hört die Skill auf Prompt-Handwerk zu sein und wird Decomposition: das Problem so zu schneiden dass jeder parallele Agent ein klar definiertes Stück angreift das nicht mit den Nachbarn überlappt. Spec sie wie du ein Team von Contractors briefen würdest, nicht wie du einen Prompt auf einen Chatbot wirfst.
Takeaway: der Hebel liegt im Spec, nicht in der Anzahl. Ein gut spezifizierter 20-Agenten-Run schlägt jedes Mal einen vagen mit 200.
Lektion 3: Dynamic Workflows nehmen dir schockierend viel Scaffolding ab
Ehre wem Ehre gebührt, meine rohen Notizen für diesen Abschnitt sagten wörtlich nur "das ist großartig." Das Fan-out, das Zusammenführen der Ergebnisse, die Koordination zwischen den Agents, die Buchführung welche These welche geschlagen hat, der adversariale Verify-Durchlauf wo Agents versuchen die Findings der anderen zu widerlegen, davon hab ich nichts gebaut. Die Orchestration macht das. Ich hatte mich auf einen Haufen Glue-Code eingestellt um 200 gleichzeitige Ergebnisse zu managen und da war einfach nichts.
Das zählt mehr als es klingt. Der Grund warum ich nie vorher ein 200-Agenten-Turnier gefahren hab ist nicht dass mir die Idee gefehlt hat, es ist dass die Infrastruktur das Projekt war, und das Projekt war es für einen Hobby-Eval-Grind nie wert. Nimm diese Steuer weg und die Rechnung dreht sich. Du bringst die Decomposition und die Specs, Claude Code bringt die Plumbing.
Lektion 4: Ja, die Token-Kosten sind heavy. Das ist der Punkt.
Reden wir über die Sache vor der alle zusammenzucken: Dynamic Workflows verbrennen Tokens. Eine Menge davon. Zweihundert Subagents die parallel reasonen sind genau so teuer wie es klingt, und "Token Discipline" ist plötzlich ein echter Begriff in der Claude-Code-Community, aus gutem Grund.
Meine Meinung: es soll teuer sein, und du solltest es größtenteils egal sein lassen. Einen Schwarm zu fahren ist eben token-heavy, das ist die Form der Arbeit, kein Bug in deiner Nutzung. Du kaufst parallele Kognition, und parallele Kognition kostet Tokens. Ich bin auf dem Claude Code Max 20x Plan, und dafür zahlt es sich beim ersten Mal aus wenn der Schwarm eine Config findet die ich nicht gefunden hätte. Wenn du auf dem Pro Plan bist, ich bin ehrlich mit dir: dieser konkrete Move ist Overkill, du knallst vor dem Mittagessen ans Limit.
Aber die eigentliche Lektion ist das Zusammenzucken selbst. Ich hab aus reiner Gewohnheit runtergeregelt, Token-Angst, bei einem Run dessen Output offensichtlich das Zehnfache seiner Kosten wert war. Dieser Instinkt ist das was du killen musst. Wenn der Wert des Ergebnisses klar den Preis der Compute schlägt, gib die Compute aus.
Takeaway: wenn ein Schwarm-Run Tokens im Wert eines Kaffees kostet und eine Woche serielles Knöpfedrehen spart, ist das keine Verschwendung, das ist Rechnen.
Wie du das Meiste aus Claude Code Dynamic Workflows rausholst
Wenn du das selbst probierst, die kurze Checkliste:
- Aktivier es richtig. Opus 4.8 plus /ultracode um Claude Code in den Multi-Agent-Modus zu schieben.
- Pin dein Modell damit Subagents Opus fahren, nicht aus Versehen Haiku.
- Spezifizier jeden Agent: Rolle, These, Constraints, Erfolgskriterien. Vage rein, generisch raus.
- Denk in Decomposition. Schneide die Aufgabe in nicht-überlappende Stücke für parallele Subagents.
- Match den Plan zur Workload: Max 20x für Schwärme, Pro für leichtere parallele Runs.
- Gib ohne Angst aus wenn der Output-Wert klar die Token-Kosten schlägt.
Was sich für mich wirklich geändert hat
Die bleibende Verschiebung war nicht der höhere Eval-Score, auch wenn ich einen gekriegt hab. Es war die Erkenntnis dass sich der Bottleneck verschoben hat. Jahrelang war das knappe Gut die Compute und das billige Gut meine Ideen, also hab ich Runs rationiert und Hypothesen gehortet. Das ist jetzt umgekehrt. Die Beschränkung ist Decomposition und Geschmack, nicht Geduld und Budget.
Der Schwarm hat also mein Denken nicht ersetzt, er hat es verlagert. Ich hab fast keine Zeit damit verbracht Experimente laufen zu lassen und fast die ganze damit zu entscheiden welche Experimente eine These wert sind: das Problem framen, in Stücke schneiden, die Agents briefen, beurteilen was zurückkommt. Das ist ein besserer Einsatz von mir.
Wenn ich eine Notiz an mein früheres Ich schicken könnte: pin deine Modelle, schreib scharfe Specs, lehn dich aufs Scaffolding, und hör auf bei der Anzeige zusammenzuzucken wenn der Output es klar wert ist. Compute ist ein Regler. Die meisten von uns fahren ihn noch auf eins.
Dreh ihn auf.
FAQ
Was ist /ultracode in Claude Code? /ultracode hebt den Reasoning-Effort von Claude Code an und schiebt es in einen tiefen Multi-Agent-Modus, verteilt Arbeit über viele Subagents und verifiziert die Ergebnisse, statt in einem einzelnen linearen Durchlauf zu antworten.
Was sind Dynamic Workflows in Claude Opus 4.8? Ein Feature bei dem Claude aus deinem Request ein JavaScript-Orchestration-Script schreibt und es im Hintergrund laufen lässt, das Dutzende bis Hunderte parallele Subagents spawnt (bis zu 1.000 pro Run) um eine große Aufgabe zu zerlegen, auszuführen, zu verifizieren und zusammenzuführen.
Verbrauchen Dynamic Workflows viele Tokens? Ja. Parallele Subagents zu fahren ist von Natur aus token-heavy. Es passt gut zum Claude Code Max 20x Plan, auf Pro knallst du schnell ans Limit.
Warum produzieren meine Subagents schwache Ergebnisse? Zwei häufige Ursachen: sie fahren still auf Haiku statt Opus (pin das Modell), oder deine Prompts sind zu vage (spezifizier Rolle, These und Constraints jedes Agents).
