TL;DR
- Claude Opus 4.8 added dynamic workflows to Claude Code: Claude writes a JavaScript orchestration script on the fly and spawns dozens to hundreds of parallel subagents to attack a task, up to 1,000 agents per run.
- I used /ultracode plus dynamic workflows to run an "autoresearch on steroids" experiment: around 200 subagents, each with its own thesis, all competing to beat my agent's best eval score.
- Biggest gotcha: it can silently spawn cheaper Haiku subagents instead of Opus. Pin your model.
- Biggest lever: specificity. Vague prompts spawn generic agents. The skill is decomposition, not agent count.
- On token usage: yes, it's heavy. On the Claude Code Max 20x plan it's worth it, on Pro it's overkill. Stop flinching at the meter when the output beats the cost.
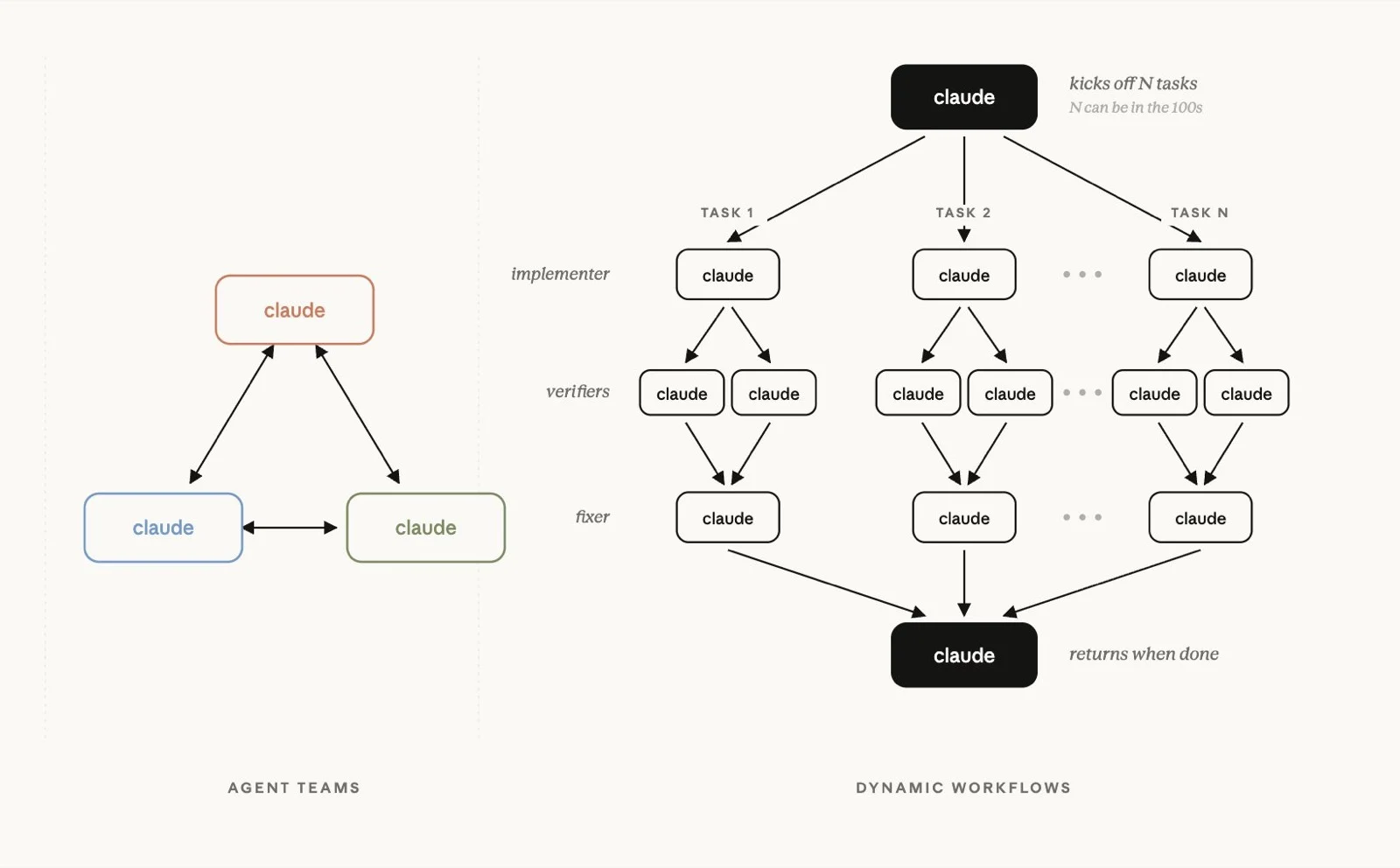
What are Claude Code dynamic workflows in Opus 4.8?
If you've only just seen the headlines about Claude Opus 4.8, here's the one-line version: alongside the model upgrade, Anthropic shipped dynamic workflows, a way for Claude Code to detect that a task is too big for a single context, automatically write an orchestration script, and run many subagents in parallel, verifying and synthesizing their results instead of grinding through one linear chain of prompts.
A few facts worth knowing before you try it:
- Claude generates a JavaScript orchestration script from your natural-language request, and a separate runtime executes it in the background.
- A single workflow can run tens to hundreds of parallel subagents, capped at around 16 concurrent and 1,000 total per execution.
- /ultracode cranks reasoning effort up and is the switch most people use to push Claude Code into this deep, multi-agent, fan-out-and-verify mode.
- Opus 4.8 also powers a fast mode that keeps Opus-level quality at higher output speed.
That's the marketing layer. Here's what it's actually like to live with.
The 2am decision that started this
I'd been grinding on the same problem for weeks: get the eval scores up on an agent I'm building. Not glamorous. Just the slow loop every practitioner knows. Change one knob, re-run the suite, watch a number move 0.3%, sigh, change another knob. One hypothesis at a time, gated entirely by how fast I could think of the next thing to try. It works, but it's slow, and a little cowardly, because you only ever test the hypotheses you have the patience to test.
I'd been reading Karpathy's stuff on autoresearch, letting a model propose and test its own experiments. Sitting there at 2am with Opus 4.8's dynamic workflows freshly enabled, a dumb, irresistible thought showed up: what if I didn't run autoresearch politely, one idea at a time, but cranked it to eleven? What if I just threw a swarm at it?
So I did. I wrote a workflow that had Claude Code spawn an army of agents, on the order of 200, each one carrying its own thesis. Each subagent's job was singular and competitive: beat the best eval score seen so far. A different hypothesis, config, and angle per agent. A tournament of ideas, all running in parallel, all hunting the same high score.
Watching the agent swarm run
I was not calm about it. I kicked it off and watched the orchestration fan out, genuinely a little stunned. Two hundred little researchers, each convinced its idea was the one. Some chased variations I'd have eventually tried myself. A bunch chased things I'd never have bothered with, and a few of those were the ones that moved the number.
That reframed the whole thing. When you try ideas serially, you're not exploring, you're rationing. You test the three things you believe in most and call it a day, because each one costs an afternoon. A swarm doesn't ration. It tries the stupid-sounding idea right next to the obvious one, because trying it is nearly free, and the stupid-sounding idea wins more often than my ego would like to admit.
But it was not "press button, receive genius." Here's what I actually learned, warts first.
Lesson 1: Check which model your subagents are actually running
This cost me real compute before I caught it. Dynamic workflows will, if you let them, quietly spawn Haiku subagents instead of Opus. So you think you've got 200 sharp researchers and you've actually got 200 fast, cheap, noticeably dumber ones doing the real thinking. Thesis generation goes shallow, experiments get timid, and you can't figure out why your brilliant swarm is producing oatmeal.
The nasty part: nothing errors out. No warning, no failed run, just quietly dumber research and a bill for it.
Takeaway: pin the model explicitly, per agent. Don't assume subagents inherit your main session's brain. If the thinking matters, and in a research swarm the thinking is the product, say Opus out loud.
Lesson 2: Vague prompts spawn generic agents
The biggest lever I found wasn't agent count. It was how precisely I specified each subagent. Lazy in ("explore ways to improve the score") and I got 200 variations of the same bland idea. At swarm scale, vague doesn't average into wisdom, it averages into mush. A hundred bland agents is just one bland agent with a worse bill.
Give each agent a sharp role, a specific thesis, and real constraints ("you believe the problem is X, test it under conditions Y, you may not touch Z") and the output gets genuinely good. This matches what Anthropic's own guidance says about parallel subagents: "use 5 parallel tasks" beats "parallelize this work," and clear scope prevents overlap.
Weekly insights on AI Architecture. No spam.
The mental model that unlocked it: more compute isn't one agent thinking harder, it's more agents running in parallel. Compute is a dial, not a bill. Once that clicks, the skill stops being prompt-craft and becomes decomposition: slicing the problem so each parallel agent attacks a well-defined piece that doesn't overlap its neighbors. Spec them like you'd brief a team of contractors, not like you'd toss a prompt at a chatbot.
Takeaway: the leverage is in the spec, not the count. A well-specified 20-agent run beats a vague 200-agent one every time.
Lesson 3: Dynamic workflows do a shocking amount of scaffolding for you
Credit where it's due, my raw notes for this section literally just said "this is great." The fan-out, the merging of results, the coordination between agents, the bookkeeping of which thesis beat which, the adversarial verification pass where agents try to refute each other's findings, I didn't build any of it. The orchestration handles it. I'd braced for a pile of glue code to manage 200 concurrent results and there was just none.
This matters more than it sounds. The reason I'd never run a 200-agent tournament before isn't that I lacked the idea, it's that the infrastructure was the project, and the project was never worth it for a hobby eval grind. Take that tax away and the calculus flips. You bring the decomposition and the specs, Claude Code brings the plumbing.
Lesson 4: Yes, the token usage is heavy. That's the point.
Let's address the thing everyone flinches at: dynamic workflows burn tokens. A lot of them. Two hundred subagents reasoning in parallel is exactly as expensive as it sounds, and "token discipline" is suddenly a real phrase in the Claude Code community for a reason.
My opinion: it should be expensive, and you should mostly stop caring. Running a swarm is supposed to be token-heavy, that's the shape of the work, not a bug in your usage. You're buying parallel cognition, and parallel cognition costs tokens. I'm on the Claude Code Max 20x plan, and for this it pays for itself the first time the swarm finds a config I wouldn't have. If you're on the Pro plan, I'll be straight with you: this specific move is overkill, you'll hit the ceiling before lunch.
But the real lesson is about the flinch itself. I kept throttling down out of pure habit, token anxiety, on a run whose output was obviously worth ten times its cost. That instinct is the thing to kill. When the value of the result clearly beats the price of the compute, spend the compute.
Takeaway: if a swarm run costs a coffee's worth of tokens and saves a week of serial knob-turning, that's not extravagance, it's arithmetic.
How to get the most out of Claude Code dynamic workflows
If you're trying this yourself, the short checklist:
- Enable it properly. Opus 4.8 plus /ultracode to push Claude Code into multi-agent mode.
- Pin your model so subagents run Opus, not Haiku by accident.
- Specify every agent: role, thesis, constraints, success criteria. Vague in, generic out.
- Think in decomposition. Carve the task into non-overlapping slices for parallel subagents.
- Match the plan to the workload: Max 20x for swarms, Pro for lighter parallel runs.
- Spend without anxiety when the output value clearly beats the token cost.
What actually changed for me
The lasting shift wasn't the higher eval score, though I got one. It was realizing the bottleneck had moved. For years the scarce thing was compute and the cheap thing was my ideas, so I rationed runs and hoarded hypotheses. That's inverted now. The constraint is decomposition and taste, not patience and budget.
So the swarm didn't replace my thinking, it relocated it. I spent almost no time running experiments and almost all of it deciding which experiments were worth a thesis: framing the problem, carving it into slices, briefing the agents, judging what came back. That's a better use of me.
If I could send one note back to past-me: pin your models, write sharp specs, lean on the scaffolding, and stop flinching at the meter when the output is clearly worth it. Compute is a dial. Most of us are still running it at one.
Turn it up.
FAQ
What is /ultracode in Claude Code? /ultracode raises Claude Code's reasoning effort and pushes it into deep, multi-agent mode, fanning out work across many subagents and verifying results, rather than answering in a single linear pass.
What are dynamic workflows in Claude Opus 4.8? A feature where Claude writes a JavaScript orchestration script from your request and runs it in the background, spawning dozens to hundreds of parallel subagents (up to 1,000 per run) to decompose, execute, verify, and synthesize a large task.
Do dynamic workflows use a lot of tokens? Yes. Running parallel subagents is token-heavy by design. It's well-suited to the Claude Code Max 20x plan, on Pro you'll hit limits fast.
Why are my subagents producing weak results? Two common causes: they're silently running on Haiku instead of Opus (pin the model), or your prompts are too vague (specify each agent's role, thesis, and constraints).
